秦永彬教授团队最新研究成果在计算机科学领域的顶级期刊《Knowledge-Based Systems》上发表
发布时间: 2023-12-04 | 查看数:2576
近日,秦永彬教授团队在计算机科学领域国际顶级学术期刊《Knowledge-Based Systems》(IF=8.8,中科院一区TOP期刊,JCR一区)上发表了题为《Deep Document Clustering via Adaptive Hybrid Representation Learning》的学术论文。论文第一作者为我院2020级博士研究生任丽娜同学,通讯作者为秦永彬教授。
《Knowledge-Based Systems》是计算机科学领域的世界顶级期刊之一,在计算机科学领域具有很高影响力,主要发表人工智能、大数据等领域高质量研究成果。

期刊《Knowledge-Based Systems》封面
聚类是文本挖掘的重要任务,为众多应用所普遍关注。其主要目标为在非监督的场景下依照数据样本的相似性关系挖掘数据集的结构,使得相似的数据样本被分配到同一组中,不相似的数据被分配到不同的组中。近年来,随着深度学习在各领域的突破性进展,深度学习与文本聚类任务结合的深度文本聚类算法受到普遍关注,成为了一个研究热点。现有深度文本聚类方法虽然初步探讨了混合语义表示的学习,但是大多采用直接融合的方法学习关联文本的结构语义表示,忽略了文本内容语义表示的重要性以及关联文本语义表示中噪音语义表示的影响,导致重要语义表示学习不足。
该论文受此启发提出了一种基于自适应混合语义表示学习的深度文本聚类模型(DCAHR),解决了混合语义表示联合优化的问题。设计了一种自适应表示增强网络(AREN),用于学习语义和结构表示的一致性信息,并利用其自适应学习相应的增强表示。DCAHR模型充分利用文本自身内容语义表示与关联文本语义表示的互补特点,有效降低了混合语义表示学习过程中语义表示缺失和噪音的影响,突破了原有深度文本聚类方法中混合语义表示学习的缺陷。
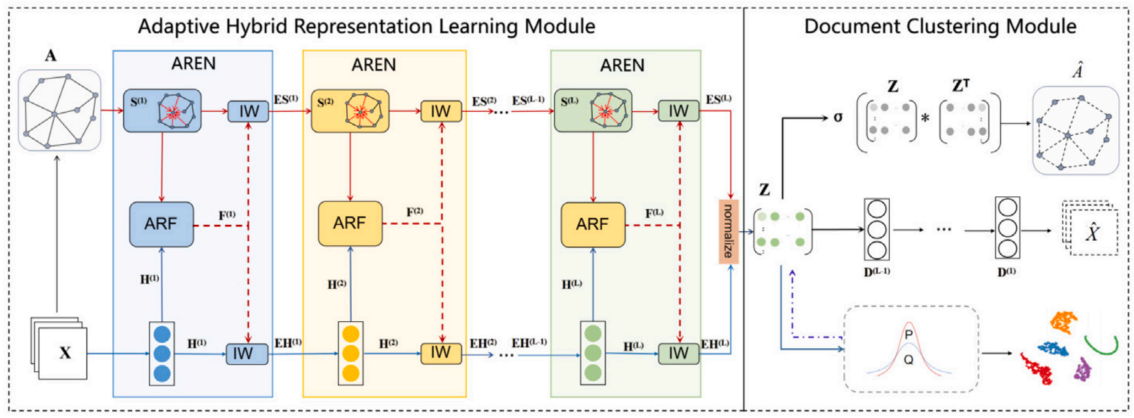
基于自适应混合语义表示学习的深度文本聚类模型图
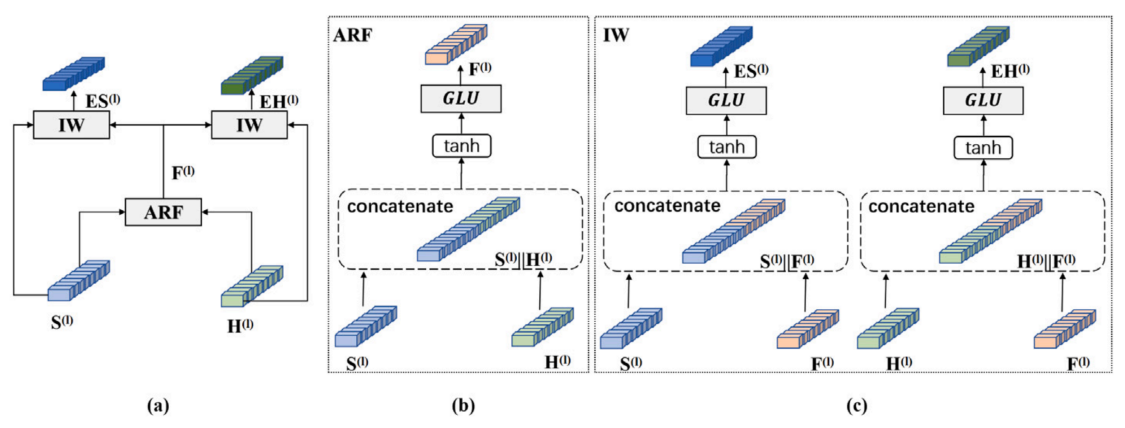
自适应表示增强网络结构图
一审:唐玮欣
二审:何 飞
三审:龙慧云